Turn Raw Product Events into Deterministic PLG Signals Natively in Snowflake
Stop burying usage data inside rigid dashboards. GrowthCues converts messy event logs into deterministic PLG signals, giving your GTM teams and AI agents the exact data foundation needed to trigger downstream GTM workflows.
- Zero Data Egress: Runs 100% securely inside your Snowflake account. Your customer data never leaves your perimeter.
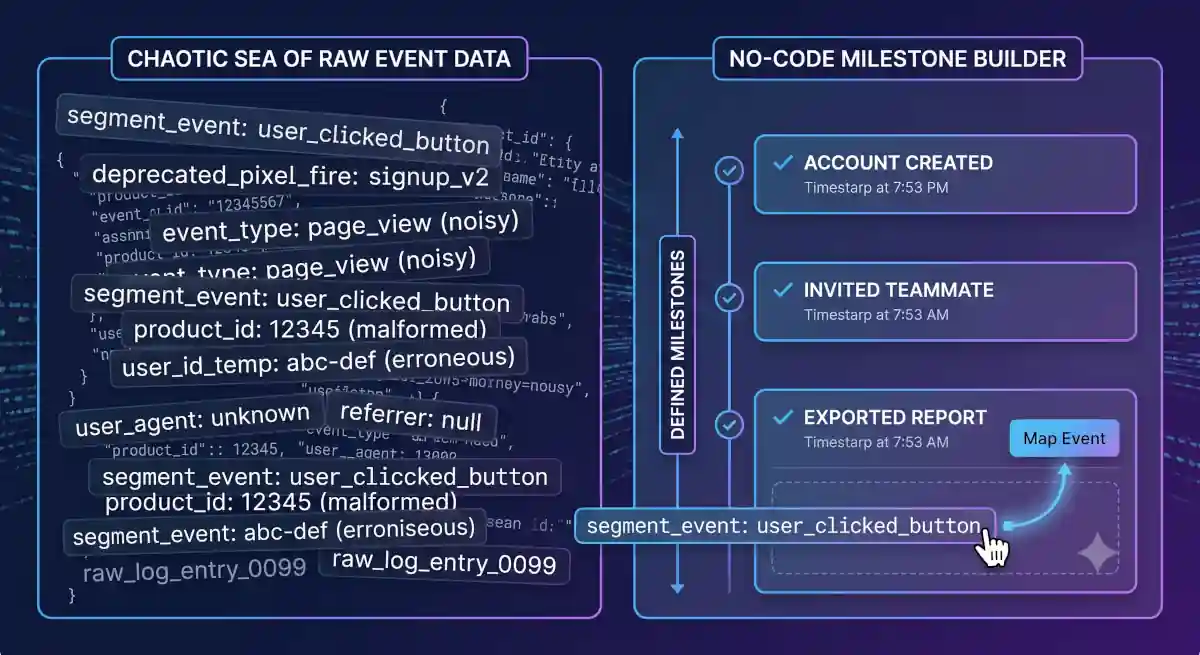
- Built-In Noise Filter: Your Segment event data is messy, and that's fine. Use our UI to select the events that matter, and our engine automatically ignores the 90% of warehouse garbage.
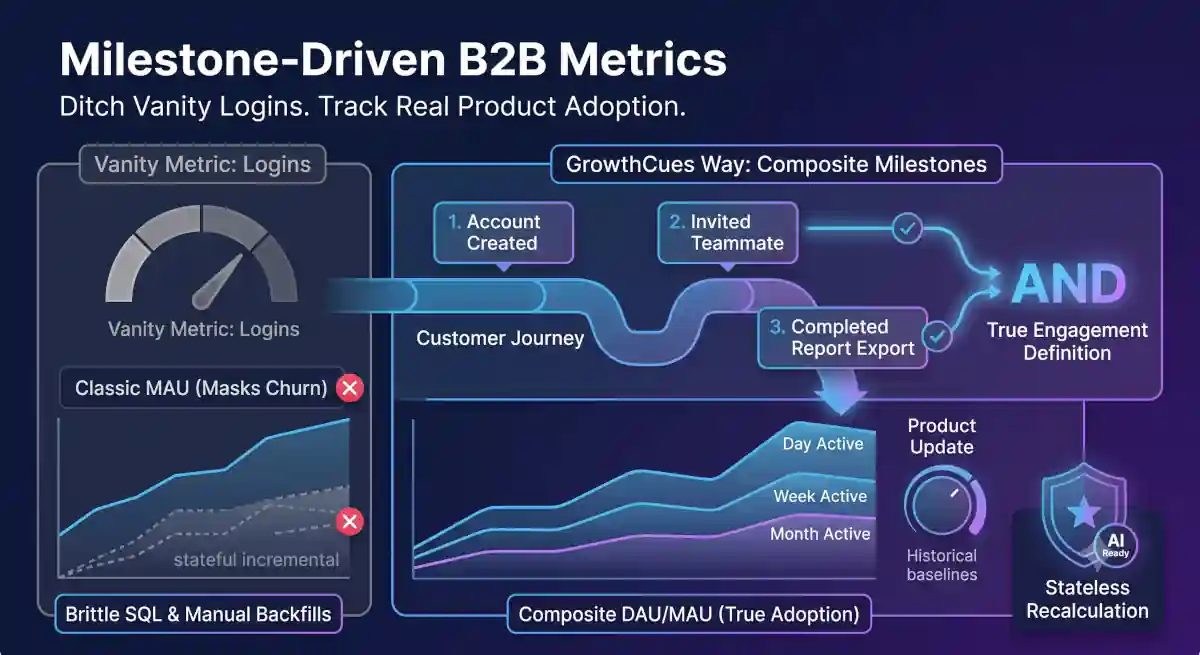
- Value-Driven Metrics: Redefine user and account activation around actual business-critical milestones rather than vanity logins or arbitrary page views.
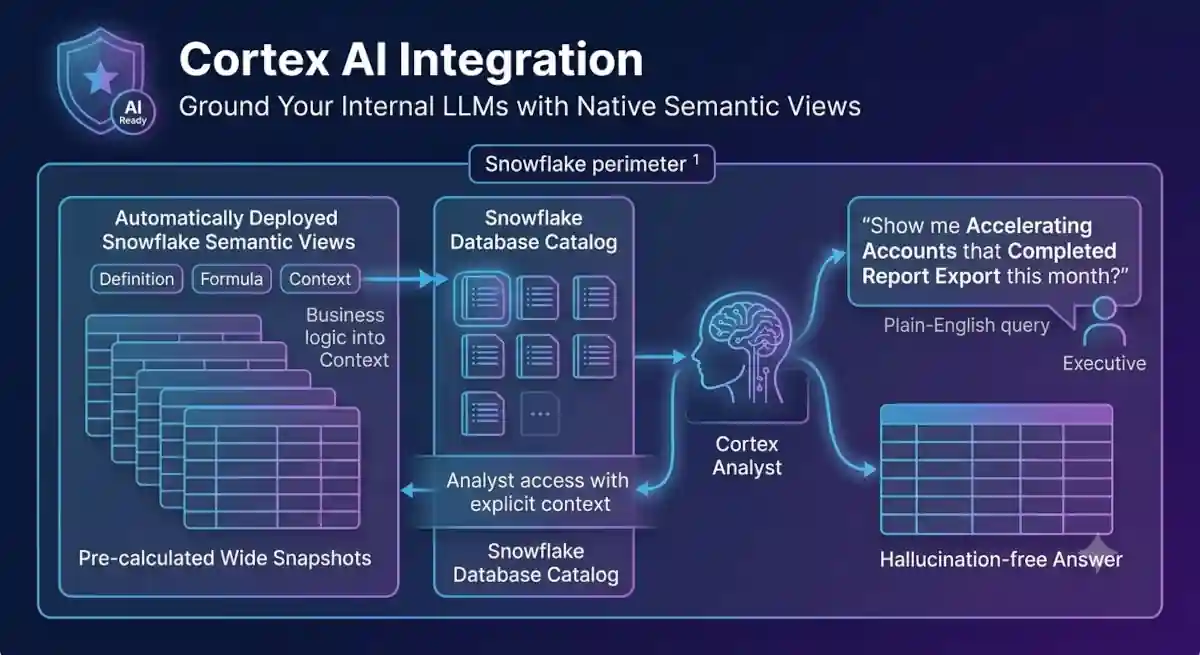
- Cortex AI Ready: Automatically deploys native Snowflake Semantic Views to ground internal LLMs, enabling hallucination-free conversational analytics.
⚡ The GrowthCues Evolution
From Brittle SQL to Snowflake-Native Intelligence
❌ Vanity Metrics: Relying on simple logins or arbitrary page views that mask true account churn risks.
📈 Milestone-Driven Health: Calculate DAU, WAU, and MAU strictly on high-value, impact-generating actions defined by your business.
❌ Unmaintainable Funnels: Writing thousands of lines of complex SQL window functions to track stateful, time-bound customer paths.
🗺️ Visual Journey Logic: A visual framework to sequence multi-step onboarding funnels and track activation stages without code.
❌ Massive InfoSec Friction: Copying and extracting your core customer event logs to external third-party SaaS servers.
🔒 100% Snowflake Native: Zero data egress. The application runs entirely within your existing cloud perimeter and security boundary.
⚙️ How it works
The Headless PLG Engine in Action
Deploy a visual GTM logic layer directly inside your warehouse. No data egress, no brittle SQL, and no custom engineering required.
Install in Minutes
Available as a native app in Snowflake Marketplace. Start in minutes! With GrowthCues as a Native App, you can launch deterministic journey tracking and automated playbooks instantly in your own Snowflake account. No brittle integrations. No data movement. No compromises.
Key Benefits
Connect Securely
Deploy GrowthCues securely from the Snowflake Marketplace directly into your account. It requires zero external network access.
Secure, Zero-Trust Architecture
Specify Product Value
Stop relying on generic, vanity "high activity" metrics like logins or page views that mask true account intent. GrowthCues gives RevOps and CS leaders a visual, no-code milestone and journey specification layer to map out exact business logic based on actual value realization.
Define Real B2B SaaS Metrics
Map Real PLG Milestones
Process Data Natively
You define the logic; GrowthCues handles the complex time-series compute. GrowthCues executes its high-performance journey engine on a resource-efficient daily batch schedule directly inside your warehouse.
Rolling Measures & Cost-Efficient Compute
Fast, Cost-Efficient Compute
Enrich and Empower Your GTM Stack
The platform doesn't just calculate data; it builds the semantic foundation for your entire GTM and AI stack. GrowthCues writes clean, calculated account lifecycle flags directly back into your Snowflake database catalog.
Power AI and Self-Service Analytics
Feed Your Existing Reverse ETL Pipes
🔑 Key Features
The Ultimate Zero-Egress GTM Engine for B2B SaaS
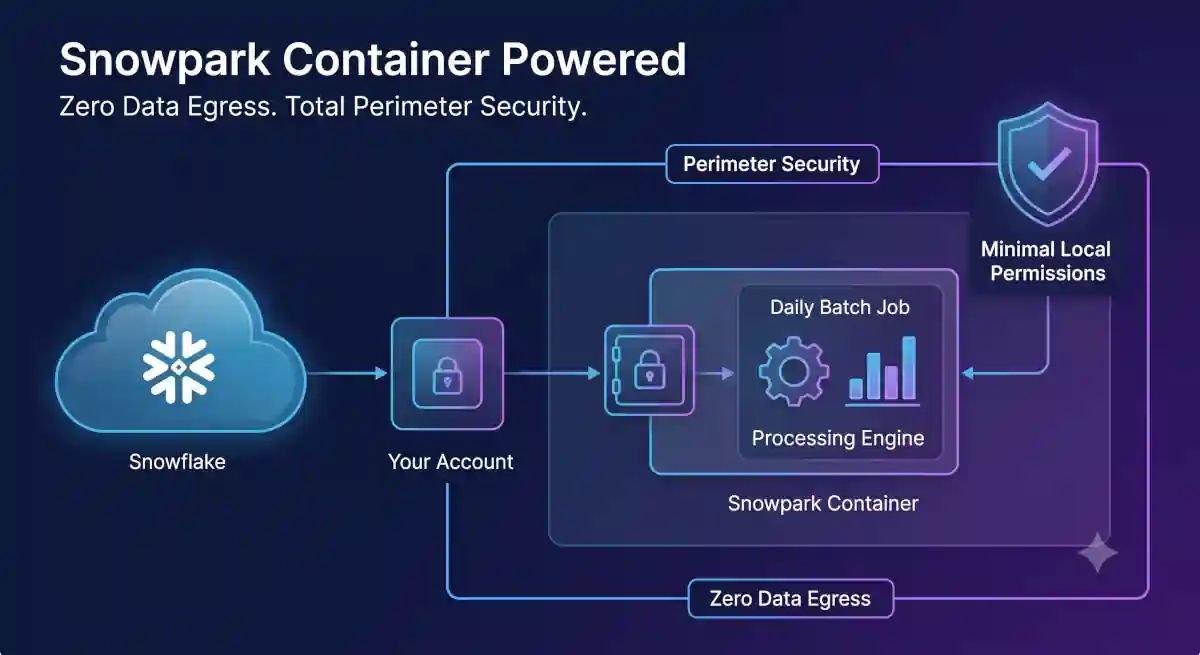
Built natively on Snowflake. Our processing engine runs inside your account using resource-efficient daily batch jobs. You grant minimal local permissions, completely bypassing security and data privacy approval bottlenecks.
Enterprise Power. Snowflake Native Simplicity.
Flat, predictable pricing based strictly on your organizational complexity. Zero data egress. Running entirely within your existing cloud budget.
GrowthCues Base
For single-product B2B SaaS teams looking to establish a pristine AI Semantic Layer and deterministic churn signals.
$15,000 / year (Billed via Snowflake)
- 100% Snowflake-Native Execution (Zero Egress)
- 1 Product Workspace (Single Segment Source)
- Unlimited Monitored Accounts & Milestones
- Instant Historical Baselines (90-Day Recalculation)
- Automated Semantic View Generation (Cortex Ready)
GrowthCues Enterprise
The complete Portfolio Intelligence tier for multi-product organizations to map cross-sell opportunities and aggregate portfolio health.
$36,000 / year (Billed via Snowflake)
- 100% Snowflake-Native Execution (Zero Egress)
- Unlimited Product Workspaces (Isolate product lines)
- Unlimited Monitored Accounts & Milestones
- Instant Historical Baselines (90-Day Recalculation)
- Unified Multi-Product Semantic Model (Query all product lines in a single Cortex AI session)
Questions & Answers
It means our product is built using the Snowflake Native App Framework and executes via Snowpark Container Services. Instead of extracting your raw customer data and moving it to external servers, our application code comes directly to your data. The entire visual rule builder UI, data processing engine, and state configuration run entirely inside your secure Snowflake perimeter.
GrowthCues functions inside a closed loop. During installation from the Snowflake Marketplace, you grant the app local read-only access to your event log schemas (like Segment or Rudderstack) and write-only access to a dedicated output schema you completely control. No API keys, no external database credentials, and no external network access (ENA) are ever required.
You can discover and activate our 30-day free trial with a single click directly inside the Snowflake Marketplace. During this month-long trial period, you get completely unrestricted access to our full premium enterprise capabilities: visual milestone modeling, value-driven journey tracking, and native semantic view deployment.
Because the app runs natively inside your own cloud account, it utilizes your existing serverless Snowflake tasks and compute pools to run its daily processing batches. GrowthCues charges a flat software licensing fee, meaning your infrastructure compute costs remain transparently managed under your main Snowflake bill.
Traditional analytics tools count simple logins or automated page views as "activity" which often creates false positives for account health downstream, in your reports and dashboards. GrowthCues allows you to define activity based on business-critical milestones (e.g., executing a core data export at least two times within a week). A user is only active if they actually derive value, providing your CS team with a completely accurate view of true adoption.
Raw warehouse data columns like momentum_delta_7d are completely meaningless to an AI agent without underlying business rules. Every time GrowthCues runs its batch processing, it automatically deploys native Snowflake Semantic Views into your database catalog. When your teams use Snowflake Cortex Analyst to query your data in plain English, the AI reads these metadata descriptions as a foundational source of truth, completely eliminating metric hallucinations.
No. GrowthCues eliminates the need for third-party data extraction tools. By writing clean, aggregated signals directly back into your robust Snowflake schemas, your data is instantly ready for native consumption. You can route alerts to Slack using Snowflake's native Alerting features, push statuses to your CRM via Snowflake's Native Connectors, or feed the data directly to your BI tools without ever paying a middleman to move your data.
Not at all. GrowthCues acts as a natural noise filter. We know most B2B SaaS event tables are full of deprecated pixels and meaningless auto-generated clicks. Our UI allows your team to visually browse your raw tables and explicitly map only the specific events that matter (e.g., clicking a specific export button). Our processing engine completely ignores the other 90% of chaotic data. You get clean, AI-ready signals without months of data engineering cleanup.